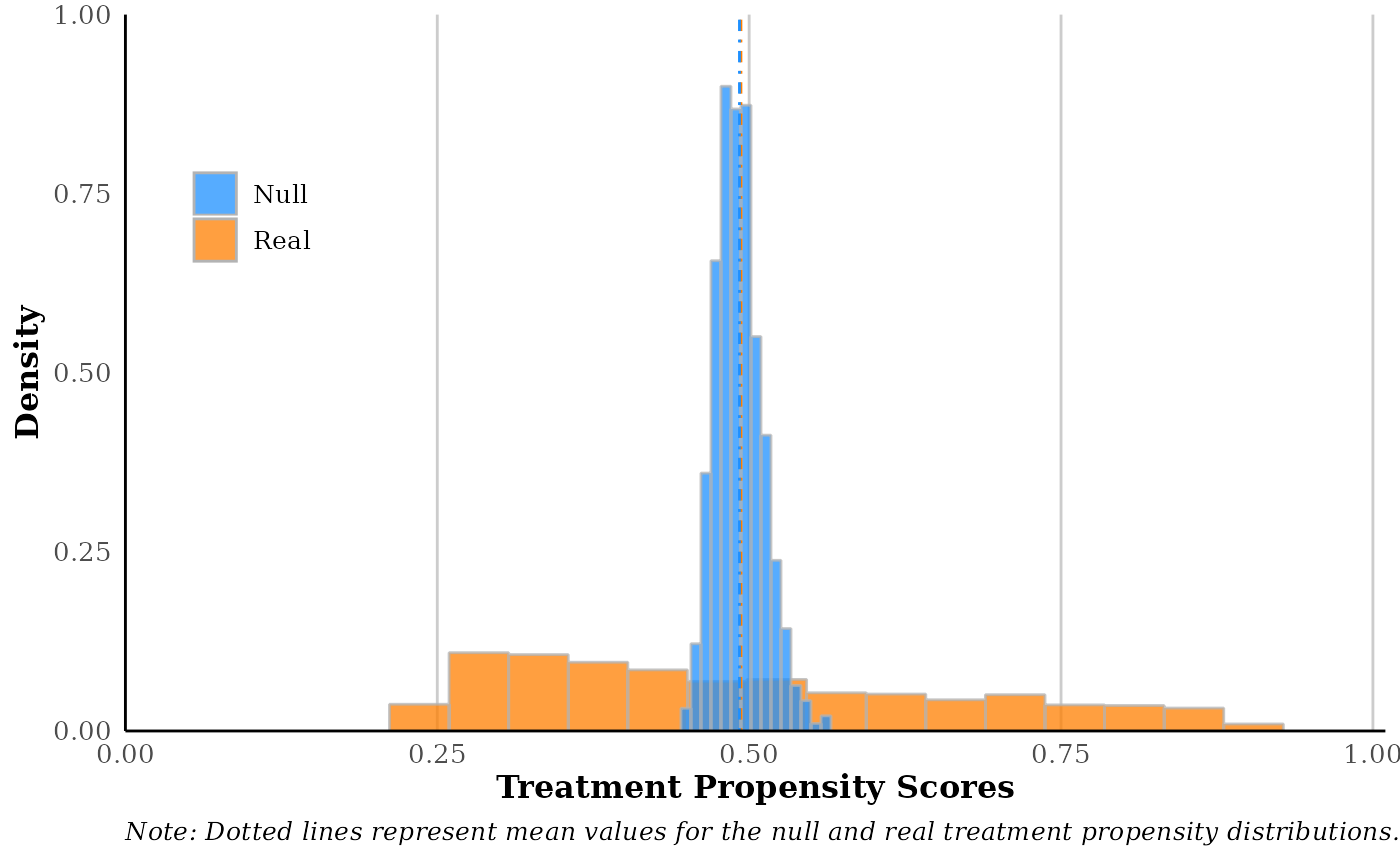
This is the main balance permutation test function. First, the function attempts to model treatment assignment (W_real) as a function of pre-treatment covariates (X). It does so using an honest, boosted random forest (see Ghosal and Hooker 2018) with built-in hyperparameter tuning. This model is used to generate real treatment propensity scores. Then, we build a second boosted random forest model using the same pre-treatment covariates and tuning parameter settings but with either simulated, or randomly permuted, treatment assignment as the outcome variable. The function proceeds to output both the real and null treatment propensity scores as well as diagnostics and a plot comparing the distributions.
The purpose of this exercise is to compare the real treatment propensity distribution to a null distribution where treatment assignment is correctly orthogonal to pre-treatment covariates. To interpret the results, it's advisable to notice any extreme, deterministic treatment propensity scores near zero or one, or any other divergences from design expectations. In general, if randomization succeeded the two distributions should closely overlap with similar means and variances. If the results are at all unclear, it's advisable to estimate average treatment effects via a method that accounts for propensity to treatment (e.g., augmented inverse propensity weighting, overlap weighting, etc.).
Usage
random_check(
W_real,
W_sim = NULL,
X,
R.seed = 1995,
grf.seed = 1995,
breaks = 25,
facet = FALSE,
clusters = NULL,
blocks = NULL
)Arguments
- W_real
Real treatment assignment vector.
- W_sim
Simulated treatment assignment vector. If not provided, permuted W_real is used.
- X
Pre-treatment covariate matrix or data frame.
- R.seed
Random seed used in set.seed (for replicability).
- grf.seed
Random seed used in grf's seed (for replicability).
- breaks
Number of breaks in output histogram. Default is 25.
- facet
facet by treatment assignment. Default is FALSE.
- clusters
Optional vector of cluster identifiers (same length as
W_real). When provided, the null permutation shuffles treatment labels at the cluster level and the propensity models receive cluster information. Treatment must be constant within each cluster.- blocks
Optional vector of block identifiers (same length as
W_real). When provided, the null permutation is restricted to within each block.
Value
A named list containing:
- prop.model.real
Fitted boosted regression forest for real treatment assignment.
- prop.model.real.tuning
Tuning parameters from the real propensity model.
- treat.props.real
Predicted treatment propensity scores for real assignment.
- imp.predictors
Variable importance scores from the real propensity model.
- prop.model.sim
Fitted boosted regression forest for simulated/permuted assignment.
- prop.model.sim.tuning
Tuning parameters from the simulated propensity model.
- treat.props.sim
Predicted treatment propensity scores for simulated assignment.
- plot.df
Data frame used to generate the diagnostic plot.
- plot
ggplot object showing overlapping propensity score distributions.
Examples
# \donttest{
n <- 1000
p <- 20
X <- matrix(rnorm(n*p,0,1),n,p)
w_real <- rbinom(n, 1, ifelse(.021 + abs(.4*X[,4] - .5*X[,8]) < 1,
.021 + abs(.4*X[,4] - .5*X[,8]), 1))
df <- data.frame(w_real,X)
r.check <- random_check(W_real = df$w_real,
X = subset(df, select = -w_real))
#> No Simulated Assignment Vector Provided, Null Distribution Generated Using Permutated Treatment Assignment.
r.check$plot
 # }
# }